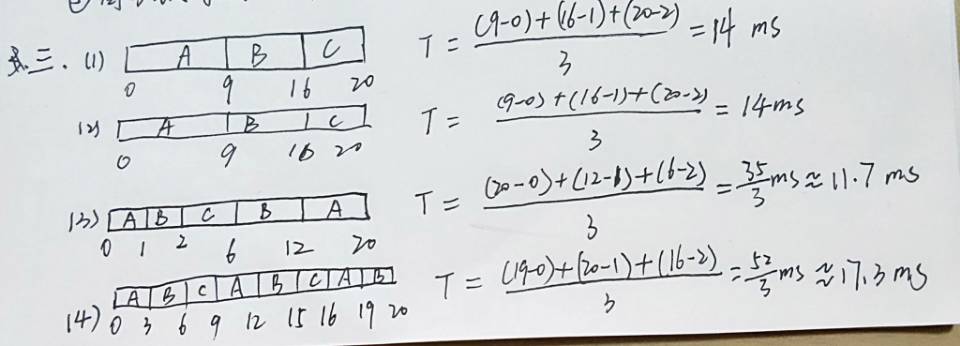考试
- 多线程+多进程api使用
- scanf不用,不用格式化输出
- 时间段提交特定题目
- 自己电脑
Task 1 熟悉Linux
详见博客 Linux操作手册
Task 2 文件读写
2.1 echo
- myecho.c的功能与系统echo程序相同
- 接受命令行参数,并将参数打印出来
- 运行程序后前面出现
./myecho- argc 是指传入参数的个数,
- argv[] 是一个指针数组,指向传递给程序的每个参数。第一个参数就是
./myecho,所以从第二个参数开始打印即可。
1 |
|
2.2 cat
- mycat.c的功能与系统cat程序相同
- mycat将指定的文件内容输出到屏幕,例子如下:
- 要求使用系统调用open/read/write/close实现
- TODO
- 文件内容超出maxn
- cat+空格命令
1 |
|
2.3 cp
- mycp.c的功能与系统cp程序相同
- 将源文件复制到目标文件,例子如下:
- 要求使用系统调用open/read/write/close实现
- TODO
1 |
|
Task 3+ 多进程题目
3.1 mysys (Task3)
- mysys的功能与系统函数system相同,要求用进程管理相关系统调用自己实现一遍
- 使用fork/exec/wait系统调用实现mysys
- 不能通过调用系统函数system实现mysys
题外话:vscode直接运行代码的话会出现问题,
---------会在最后输出,在命令行运行并没问题。目前原因还不知道5月15日:在实现Task5时发现功能已经具备,这才察觉到Task3写错了,原来使用
execl("/bin/sh", "sh", "-c", command, NULL);,其实这与调用系统函数system无异。第一个参数应该指定可命令的路径,而不是直接指定sh。
1 |
|
3.2 sh1.c (Task4)
- 该程序读取用户输入的命令,调用函数mysys(上一个作业)执行用户的命令
1 |
|
3.3 sh2.c (Task5)
- 实现shell程序,要求在第1版的基础上,添加如下功能:实现文件重定向
1 |
|
3.4 sh3.c (Task6)
实现shell程序,要求在第2版的基础上,添加如下功能:
- 实现管道
- 只要求连接两个命令,不要求连接多个命令
- 不要求同时处理管道和重定向
- 考虑如何实现管道和文件重定向,暂不做强制要求
此次作业遇到诸多问题,消费时间过长,主要是要静下来、沉下来,问题如下:
- strtok返回参数问题:返回值无法打印复制等,报
segmentation fault错误, 需要加个头文件#include <string.h>- pipe要在fork之前
- 初步实现的代码执行完
cat /etc/passwd | wc -l后就立马退出程序,不知道是什么原因为实现进阶功能,后续打算参考
MIT6.828 homework2:shell进行实现。参考:
1 |
|
1 | /* MIT6.828 homework2:shell */ |
Task 7+ 多线程题目
7.1 pi1.c (Task7)
使用2个线程根据莱布尼兹级数计算PI:
- 莱布尼兹级数公式: 1 - 1/3 + 1/5 - 1/7 + 1/9 - … = PI/4
- 主线程创建1个辅助线程
- 主线程计算级数的前半部分
- 辅助线程计算级数的后半部分
- 主线程等待辅助线程运行結束后,将前半部分和后半部分相加
1 |
|
7.2 pi2.c (Task7)
使用N个线程根据莱布尼兹级数计算PI:
- 与上一题类似,但本题更加通用化,能适应N个核心
- 主线程创建N个辅助线程
- 每个辅助线程计算一部分任务,并将结果返回
- 主线程等待N个辅助线程运行结束,将所有辅助线程的结果累加
- 本题要求 1: 使用线程参数,消除程序中的代码重复
- 本题要求 2: 不能使用全局变量存储线程返回值
1 |
|
7.3 sort.c(Task 8)
多线程排序
- 主线程创建两个辅助线程
- 辅助线程1使用选择排序算法对数组的前半部分排序
- 辅助线程2使用选择排序算法对数组的后半部分排序
- 主线程等待辅助线程运行結束后,使用归并排序算法归并子线程的计算结果
- 本题要求 1: 使用线程参数,消除程序中的代码重复
1 |
|
7.4 pc1.c(Task 9)
- 系统中有3个线程:生产者、计算者、消费者
- 系统中有2个容量为4的缓冲区:buffer1、buffer2
- 生产者生产’a’、‘b’、‘c’、‘d’、‘e’、‘f’、‘g’、'h’八个字符,放入到buffer1
- 计算者从buffer1取出字符,将小写字符转换为大写字符,放入到buffer2
- 消费者从buffer2取出字符,将其打印到屏幕上
1 |
|
7.5 pc2.c(Task 10)
- 功能和前面的实验相同,使用信号量解决
1 |
|
Task 11+考试
11.2 ring.c
1、实现线循环
2、创建N个线程
N个线程构成一个环
主线程向T1发送数据0
T1收到数据后,将数据加1,向T2发送数据1
T2收到数据后,将数据加1,向T3发送数据2
T3收到数据后,将数据加1,向T4发送数据3
…
3、创建N个缓冲区
4、每个线程有一个输入缓冲和一个输出缓冲
5、最终的系统结构如下
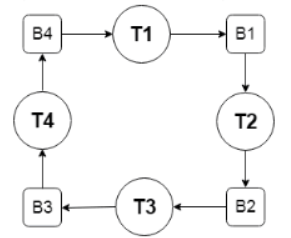
6、本程序不能使用任何全局变量,如果使用了全局变量,本题没有得分
1 |
|
1 |
|
11.2 多消费者+多生产者
1 | //现有一个水果盘,一次只能放一个水果 |
1 | //现有一个水果盘,一次只能放一个水果 |
随堂作业
Todo 1 进程的内存布局
要求
一般操作系统中,进程的每个段内部地址均连续,但段与段的相对次序可能不同。用C/C++语言写一个小程序,探测一个操作系统中进程的各段的相对位置(输出次序即可)。
理论基础
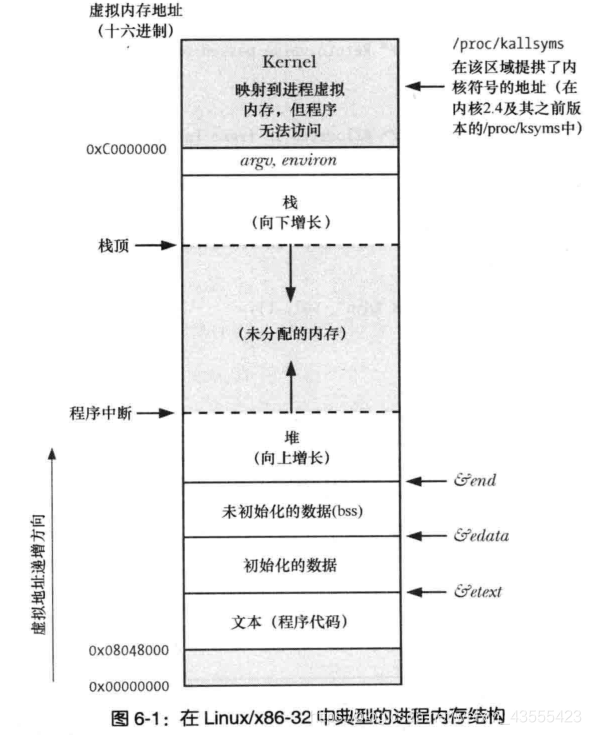
| 栈(stack) | 由编译器自动分配、翻译。存放函数的参数值和局部变量值。操作方式类似数据结构中的栈 |
|---|---|
| 堆(heap) | 由程序员分配释放。程序员不释放,程序结束时有可能由OS释放。与数据结构中的堆不同,操作方式类似于链表 |
| bss | 存放未初始化的全局变量和静态变量 |
| 数据段data | 存放初始化之后的全局变量、静态变量和常量 |
| 代码段text | 程序代码主体,函数主体等。注意为二进制格式 |
Linux 为 C 语言编程环境提供了 3 个全局符号(symbol):etext、 edata 和 end,可在程序内使用这些符号以获取相应程序文本段、初始化数据段和非初始化数据段结尾处下一字节的地址。
源代码
1 |
|
运行结果
下面分别在Linux、windows、macos系统上测试程序:
Linux(Ubuntu 18.04.2 LTS)
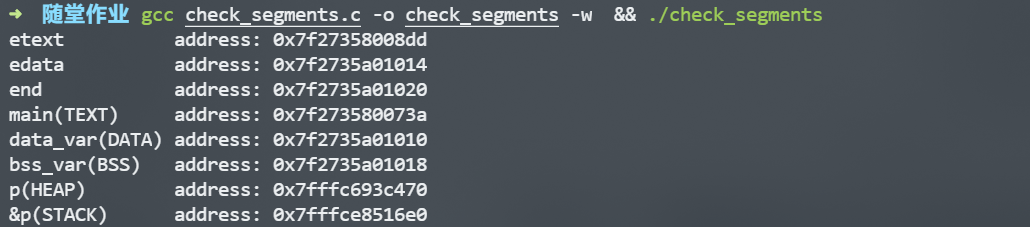
从打印结果可知:
- TEXT段在地址
0x7f27358008dd以下,DATA段的地址范围是:0x7f27358008dd - 0x7f2735a01014,BSS段的地址范围是:0x7f2735a01014 - 0x7f2735a01020 main的地址为0x7f273580073a,在TEXT段;初始化全局变量data_var的地址为0x7f2735a01010,在DATA段; 未初始化全局变量bss_var的地址为0x7f2735a01018,在 BSS 段内;- char* 变量 p 的值是
0x7fffc693c470,也就是由 malloc() 分配的一块内存空间的首地址,这块内存就在堆中;但是 p 本身存放在栈里,地址为0x7fffce8516e0 - 综上,各段的相对位置(地址由低到高):TEXT段、DATA段、BSS段、堆、栈。
Windows 10


从打印结果可知:TEXT段、DATA段、BSS段、栈的相对位置与linux、macos相同,只有堆的位置比较特殊,每次测试结果变化较大。
翻阅《Windows核心编程》:
- Windows下的堆主要有两种,进程的默认堆和自己创建的私有堆。
- 在程序启动时,系统在刚刚创建的进程虚拟地址空间中创建一个进程的默认堆,而且程序也可以通过 HeapCreate 函数来调用 ntdll 中的RtlCreateHeap 来创建自己的私有堆,所以一个进程中可以存在多个堆。
- Windows下的malloc通过Win32 API HeapAlloc来实现,所以申请的堆空间来自私有堆。
推测:
-
默认堆遵守上面的经典模型,私有堆分配可能比较随意。
-
通过调用
GetProcessHeap()来获取默认堆的位置,可能会出现想要的结果。
但是仍然存在上述问题:


最后在知乎上找到了答案:
Windows的进程地址空间分布跟上面说的简化的Linux/x86模型颇不一样。
就算在没有ASLR的老Windows上也已经很不一样,有了ASLR之后就更加不一样了。在Windows上不应该对栈和堆的相对位置做任何假设。
要想看个清楚Windows的进程地址空间长啥样,可以用Sysinternals出品的VMMap看看。
使用VMMap查看:
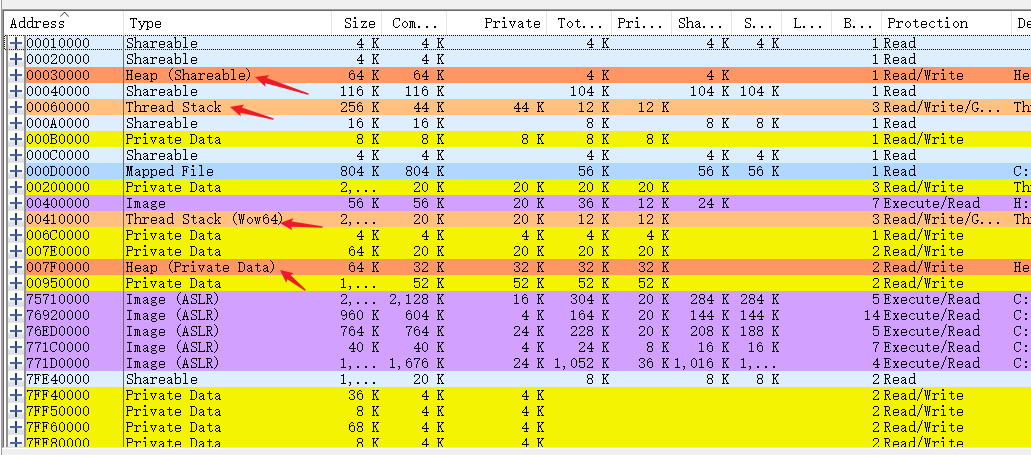
macOS

从打印结果可知:各段的相对位置(地址由低到高):TEXT段、DATA段、BSS段、堆、栈。
总结
在简化的32位Linux/x86进程地址空间模型里,(主线程的)栈空间确实比堆空间的地址要高——它已经占据了用户态地址空间的最高可分配的区域,并且向下(向低地址)增长。借用Gustavo Duarte的Anatomy of a Program in Memory里的图:
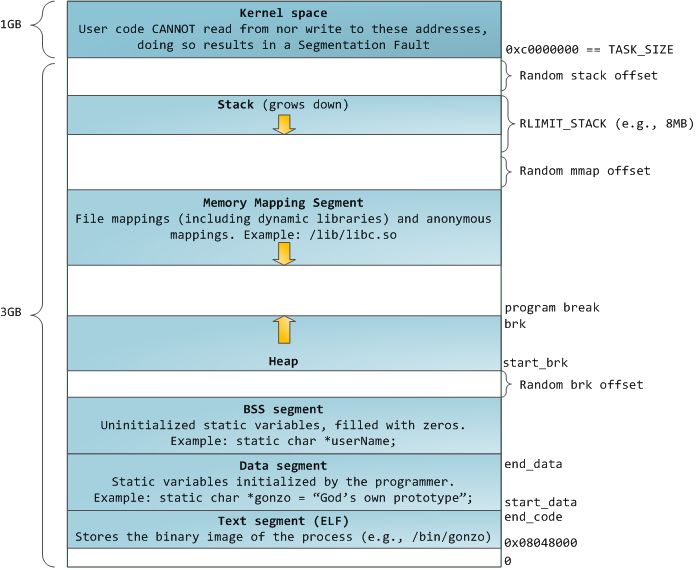
《程序员的自我修养》也说栈的地址比堆高,栈是向下增长的,堆是向上增长的。 这个说法其实不够严谨。而且上图是简化模型,会有特例:
- 虽然传统上,Linux上的malloc实现会使用
brk()/sbrk()(这俩构成了上图中Heap所示的部分,这也是Linux自身所认为是heap的地方,用pmap可以看到这里被标记为[heap]),但这并不是必须的;一个malloc()完全可以只用或基本上只用mmap()来实现,此时一般说的“Heap”(malloc-heap)就不一定在上图Heap(Linux heap)所示部分,而会在Memory Mapping Segment部分散布开来。不同版本的Linux在分配未指定起始地址的mmap()时用的顺序不一样,并不保证某种顺序。而且mmap()分配到的空间是有可能出现在低于主可执行程序映射进来的text Segment所在的位置。 - Linux上多线程进程中,“线程”其实是一组共享虚拟地址空间的进程。只有主线程的栈是按照上面图示分布,其它线程的栈的位置其实是“随机”的——它们可以由pthread_create()调用mmap()来分配,也可以由程序自己调用mmap()之后把地址传给pthread_create()。既然是mmap()来的,其它线程的栈出现在
Memory Mapping Segment的任意位置都不出奇,与用于实现malloc()用的mmap()空间很可能是交错出现的。
至于Windows的进程地址空间分布跟上面说的简化的Linux/x86模型颇不一样。就算在没有ASLR的老Windows上也已经很不一样,有了ASLR之后就更加不一样了。
在Windows上不应该对栈和堆的相对位置做任何假设。
要想看清楚Windows的进程地址空间布局,可以用Sysinternals出品的VMMap看看。
参考
- C语言易错点汇总(二)
- 程序内存空间(代码段、数据段、堆栈段)
- C语言中内存分布及程序运行中(BSS段、数据段、代码段、堆栈)
- Windows私有堆的使用
- 浅析Windows下堆的结构
- 堆、栈的地址高低? 栈的增长方向?
Todo 2 进程相关
一、选择题
-
如果操作系统采用了非抢占式进程调度算法,则进程不可能出现以下哪种状态转换? B
A.执行到阻塞 B. 执行到就绪 C. 阻塞到就绪 D. 就绪到执行
-
进程调度算法在选择进程时,只考虑处于哪个状态的进程? A
A.就绪 B.阻塞 C.执行 D.结束
-
子程序的返回地址一般存在 A
A.栈B.堆C.数据段D.代码段
-
哪个调度算法只有抢占式版本? D
A.先到先服务B. 短作业优先C. 优先级调度D. 轮转调度
二、概念理解及应用
T1(4分)
问题:为了解决能够同时服务多个客户的目的,开发人员设计了多线程程序,每次有新用户连接时创建一个新的服务线程,服务结束时销毁线程;同时,为了防止服务器瘫瘓,限制了服务线程的总数量为100个。但是在运行过程中,不断创建销毁线程引入了不必要的额外开销,你有什么办法避免这个开销?你的办法有什么缺点?
解答如下:
采用线程池,把宝贵的资源放到一个池子中;每次使用都从里面获取,用完之后又放回池子供其他人使用。主要流程图如下:
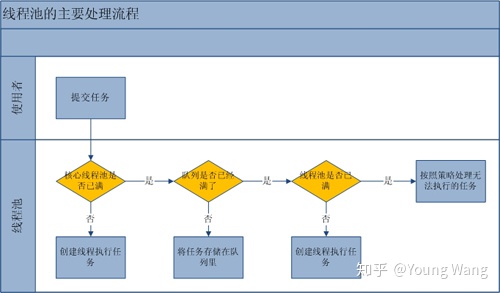
优点:
- 降低资源开销:由于线程是反复利用的,降低了创建线程分配资源和销毁线程的开销。
- 提高响应速度:由于线程是提前预热的,因此减少了创建线程这段时间的开销。
- 提高系统资源可管理性:使用线程池统一分配、管理和监控。
缺点:
- 当客户少时浪费资源
- 一个根本性的缺陷:连续争用问题。也就是多个线程在申请任务时,为了合理地分配任务要付出锁资源,对比快速的任务执行来说,这部分申请的损耗是巨大的。
参考:https://zhuanlan.zhihu.com/p/161628226
T2(4分)
问题:《Unix编程艺术》提倡使用多进程编程,而不是多线程编程。你觉得可能的原因是什么?
解答如下:
- 多进程,本质上就可以避免多线程『共享内存数据』产生的 “corruotped memory” 问题;
- 多线程的程序非常难以正确的编写;
- 难以调试: 因为 数据依赖,时间依赖
- 线程破坏了抽象: 无法设计出模块化的程序
- 因为锁导致回调无法完成
- 进程隔离性好,一个进程挂了不影响另外一个进程。
参考:
三、计算题
现有3个进程A、B、C到达时间和预计运行时间如下表所示。要求画出不同调度算法下进程运行的甘特图,并计算进程的平均周转时间。
| 进程编号 | 到达时间(毫秒) | 执行时间(毫秒) |
|---|---|---|
| A | 0 | 9 |
| B | 1 | 7 |
| C | 2 | 4 |
- 先到先服务调度算法
- 短作业优先(非抢占)
- 抢占式短作业优先算法
- 时间片轮转算法(时间片为3毫秒)
改错:
T2:A C B 13ms